Scrapping d'une bibliothèque en ligne
Scrapping d'une bibliothèque en ligne
19 septembre 2021
Technologies: Python, BeautifulSoup
Réalisé par:
-
 Anaïs Gatard
Anaïs Gatard
Suivre les prix des livres d'occasion sur des sites web : l'objectif est de récupérer automatiquement des données sur un site web afin de les exploiter.
Enjeu et solution :
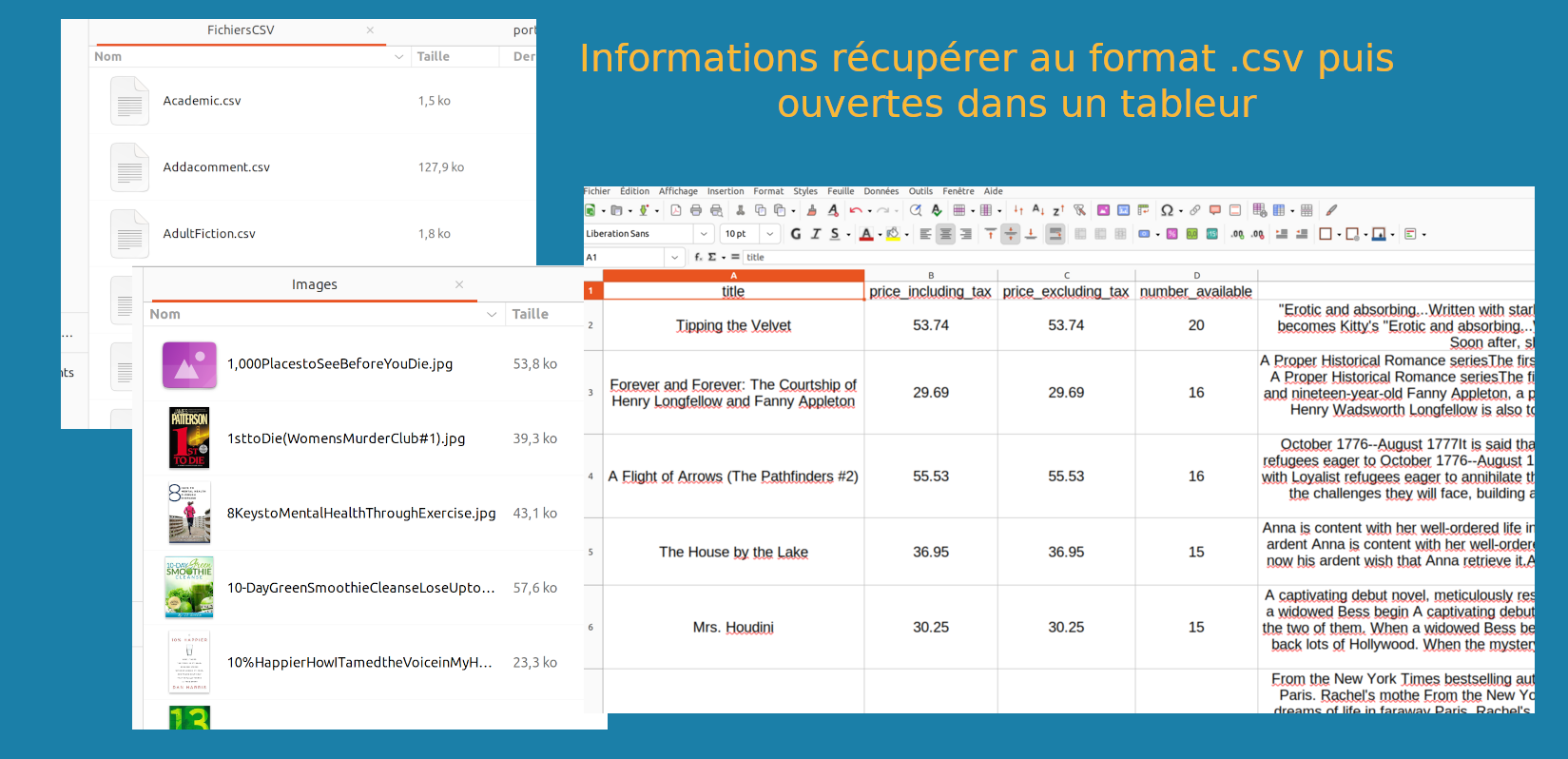
Le suivi manuel des prix des livres d'occasion sur les sites concurrents était trop fastidieux : trop de livres, trop de sites. Cet outil permet de récupérer automatiquement les données dans des documents au format .csv ainsi que les images des couvertures qui sont stockées dans un dossier.
Dans notre outil :
Le projet mené ici va chercher les informations sur ce site https://books.toscrape.com
Les données récupérées pour chaque livre sont les suivante :
- l'url de la page produit
- le titre,
- les prix HT et TTC
- la quantité disponible
- la description du produit
- la catégorie
- évaluation
- url de l'image
Ces données sont stockées dans un fichier .csv qu'il est possible d'utiliser tel quel grâce à d'autres scripts ou d'ouvrir dans des tableurs.

Illustration du projet de web scrapping